
A while ago, I came across an interesting project where someone analysed their iMessages history. While I couldn’t track down that specific project, here’s another example of someone from Reddit analyzing 4 years of iMessage history with his long distance girlfriend. Having been inspired by this and a few similar projects, I decided to take a crack at it.
BAETA
The BAE Texts Analysis (BAETA – pronounced bay-ta) project was designed to analyze text messages between bae and I. There were also a few constraints to keep in mind:
- Ability to analyze messages from both Google Voice and iOS
- Ability to visualize findings
- Ability to replicate the process for the future
With these constraints in mind, I figured the best way to approach this, was with the following tools
- Data scripting – Python with the following modules/packages
- bs4 a.k.a BeautifulSoup (you’ll see why below)
- nltk – for NLP (Stemming / Lemmatization)
- Data Storage – SQL Server
- Data Visualization – Tableau / Power BI
Collecting Data
Google Voice
With some of my messages on Google voice, I had to figure out a way to collect this data. A quick search led me to Google Takeout. Sign in to my account, select all the data I want Google to zip up (depending on your data history this could take a while), and once all done, I get an email saying my data is ready for download. I followed the steps and, voila, I have all my history from Google Voice downloaded to my computer with the following structure

As you can see, all texts are housed within files with the name Text. Here’s a snippet from one of the files.

Now that I know what the structure of a text / conversation looks like, I use the BeautifulSoup module from Python to navigate the document structure and extract the information I need.
iMessage
In order to get access to iMessages I needed three things
- A Macbook – there are articles out there that talked about how creating an iTunes backups could give me access to my texts and after failing a couple of attempts (perhaps I could’ve resolved this with more troubleshooting) on a Windows machine, I decided to switch tactics and use a Macbook instead
- Messages App on Mac OS – Once on the Mac, I had to set it up to sync my iMessages. Here’s an article that gave me more information on where I needed to look for the required file. What I needed to find, here, was a chat.db file that was generated as a consequence of the iMessage sync. This sqlite database houses all the chats and I can hone in on what i’m looking for from there.
- SQLite DB Browser – Once I had the chat.db file from step#2, I moved it to my Windows machine and got the DB Browser for SQLite that helps browse the data within the chat.db file. Here’s what the db structure looked like.

Now that I know what’s in the database, I try to figure out what tables are likely to contain the data I need – message, chat and chat_message_join. The message table has the actual message but I’m also going to need some other info
- ROWID to join with message_id from the chat_message_join table
- chat_id from the chat_message_join to join against the ROWID from the chat table
- epoch time manipulation – the article I linked to in the section above, gives excellent guidance as to what needs to be done to convert the epoch time to human readable time.
Python Scripting
Once I got a handle on what information was where, I knew I wanted to extract and retain the following key pieces of information from both data sets
- Message Author – who sent a message
- Message Time – what time was the message sent
- Message – the actual message itself
And now that I know what I want from my source data, I wrote a Python program to do 3 things
- Extract key information from Google Voice Takeout data
- Extract key information from iMessage Data
- Analyse the message content from the extracted data – as part of the exercise I also wanted to analyse what words / emojis were used the most
- Store the data for later use – write it to a db within my local SQL Server instance
Notes
While creating the script and figuring out how to store the data, there were a couple of things I had to keep in the back of my mind.
- utf-8 encoding – the data from Google Voice needed to be utf-8 encoded
- utf-8 encoding on sql server table – in order to retain the encoding when data was written to the table, I needed to use nvarchar as the column datatype as opposed to the standard varchar
Data Visualization
Now that I extracted the information and put it into tables within my db, it’s time to start visualizing. I did a version of all visualizations in Tableau and kept hitting roadblocks with Unicode displays. Power BI on the other hand, had no such issues. In any case, I wanted to answer the following questions.
Who Texts More?

Do Messaging Habits (message count) Change With Platform?

Messaging Over Time

Who Initiates Conversations

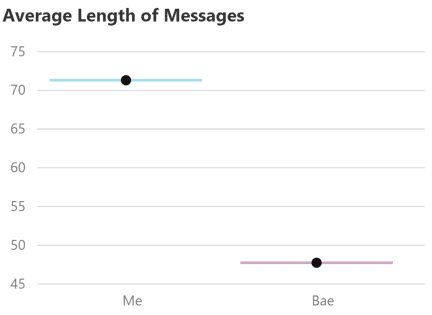
Who Talks More
Word & Emoji Analysis

Future Enhancements
Having answered the questions I set out to, there are a couple of things I would like to do in the next iteration of this project
- Sentiment Analysis – scour texts and assign a sentiment score to either the text themselves on some cluster / aggregation of them
- Word Use By Author – what words use trends can we find by looking at messages from each author
- Visualization – Use the workarounds for the Unicode character roadblocks in Tableau (although it’s a complete shame that a powerful tool like Tableau has this as a problem to begin with) and publish to Tableau
Conclusion
This was such a fun project to undertake.Besides sharpening some old skills and learning new ones, the most important part was sharing this with Bae and while she doesn’t share the same nerd level of enthusiasm as me, it was certainly quite exciting. And with the project base all set, it’s just a matter of time before I return and work on some of the future enhancements.